henri-allauch
-
Compteur de contenus
972 -
Inscription
-
Dernière visite
-
Jours gagnés
30
Tout ce qui a été posté par henri-allauch
-
Oui mais comme j'utilise déjà /api/redreshStates pour lancer des fonctions de QA. ( ça me remplace les trigger de scènes ) et je ne voulais pas alourdir ce code. Disons que J'ai voulu essayer avec autre chose .. de plus c'est un QA un peu marginal . Les événements retournés sont limités par un filtre sur eventType lors de l'api.get. j'en demande numberOfRecords=100 et si #events > 100 - Warning Pour le moment j'en ai entre 2 et 30 par requête toute les minutes; Mais dans le principe tu as raison chacune de ces deux api à une fonction logique spécifique
-
En fait je m'en suis rendu compte car je voulais journaliser en externe quelques éléments particuliers au fil du temps. Comme tu le dis le lastId c'est utile pour remonter dans le temps. Donc pour réaliser cela, j'utilise le timestamp le plus élevé (récent) du json récupéré pour l'ajouter à la requête suivante par ......&from=" .. tostring( timestamp + 1)
-
On récupère les éléments antérieurs à lastId alors qu'on devrait les ignorer et retrouver les plus récents non ? Exemple : http://192.168.1.53/api/events/history?eventType=DevicePropertyUpdatedEvent&lastId=1502913&numberOfRecords=5 [ {"data":{"id":136,"newValue":22.38,"oldValue":22.31,"property":"value"},"id":1502911,"objects":[{"id":136,"type":"device"}],"sourceId":0,"sourceType":"system","timestamp":1620291395,"type":"DevicePropertyUpdatedEvent"}, {"data":{"id":135,"newValue":26.69,"oldValue":26.75,"property":"value"},"id":1502909,"objects":[{"id":135,"type":"device"}],"sourceId":0,"sourceType":"system","timestamp":1620291394,"type":"DevicePropertyUpdatedEvent"}, {"data":{"id":130,"newValue":30.56,"oldValue":30.62,"property":"value"},"id":1502907,"objects":[{"id":130,"type":"device"}],"sourceId":0,"sourceType":"system","timestamp":1620291393,"type":"DevicePropertyUpdatedEvent"}, {"data":{"id":129,"newValue":31.31,"oldValue":31.38,"property":"value"},"id":1502905,"objects":[{"id":129,"type":"device"}],"sourceId":0,"sourceType":"system","timestamp":1620291392,"type":"DevicePropertyUpdatedEvent"}, {"data":{"id":127,"newValue":29.75,"oldValue":29.81,"property":"value"},"id":1502903,"objects":[{"id":127,"type":"device"}],"sourceId":0,"sourceType":"system","timestamp":1620291391,"type":"DevicePropertyUpdatedEvent"} ] Dans le swager c'est pareil Pourtant : requests with id<=lastId will be skipped (only more recent entries then lastId will be returned) Quelques chose m'échappe
-
Ah OK alors c'est que la connexion est meilleure avec NETATMO c'est jour-ci car sur 48 heures qu'une seule erreur au lieu de 10 à 20 par jour Comme quoi avant de tirer des conclusions ...
-
j'ai supprimé le paramètre timeout sur self.http = net.HTTPClient({timeout=10000}) La valeur par défaut étant je crois 30000 ms -- ça diminue nettement les messages d'erreur de connexion dans les traces
-

Quick App - Xiaomi Roborock Vacuum
henri-allauch a répondu à un(e) sujet de Lazer dans Quick App Developpeur
Mais tout de même quand on met le qa disable dans avancé, on est obligé de faire sauvegarde pour enregistrer cet état. Le qa redémarre donc son init : il pourrait s'arrêter seul. Il ont oublié de coder ou il y a une raison qui m'échappe ? Je n'ai rien vu dans la doc -
Quick App - Xiaomi Roborock Vacuum
henri-allauch a répondu à un(e) sujet de Lazer dans Quick App Developpeur
J'ai aussi pensé à ce mode de désactivation, mais je me suis arrêté en voyant que le lua tournait malgré que le QA soit noté enabled = false. Il faut donc tester dans le Init la valeur du Enable ? Si j'utilise l'api : local dev = api.get("/devices/347" ) , dev.enabled contient bien tue ou false OK par contre : fibaro.getValue(347, "enabled")) me rend toujours nil ??? Existe t'il un equivalent à getSelfID() des VD de la HC2 Ou il y a plus simple et je n'ai pas la solution -
Bon anniversaire @Domodial c'est l'avantage du forum on ne se connait pas forcément, mais on se côtoie.
-
Je l'ai déjà dit mais je précise que c'est grâce au forum que mon transfert a pû se réaliser Les explications et les conseils y sont nombreux Il y a une foule d'informations utiles Merci
-
@Guru Hc2 passerelle de la hc3 je ne sais pas mais sur ce forum on doit parler des passerelles possibles Par contre la portée zwave est bien meilleure que la hc3 Le Qa Netatmo tourne bien
-
Aucune idée je n'ai pas utilisé l'outil de migration j'ai dissocié un a un mes devices de la HC2 pour les ré-associer à la HC3 et écrit un nouveau code Puis j'ai supprimé tous les codes de la HC2 et Shutdown de celle-ci
-
@Guru Ma Hc2 fonctionnait parfaitement. j'aurais pu en rester là. C'est certes du boulot mais ça occupe et à présent tout a été transféré et la hc2 est OFF depuis une dizaine de jour. Tout est fonctionnel, et surtout prêt à des nouveautés. Un simple conseil, ne pas se presser, prendre la HC3 en main par des tests avant de foncer vers une migration aveugle. Ne pas hésiter de tout réorganiser. Comme beaucoup ici je pense qu'on est au début d'une nouvelle histoire ... en tout cas moi je le souhaite
-
Pour Infos Dès le début j'ai eu avant de commencer sérieusement ma migration 2 reboot par semaine. Puis pendant ma "migration" ( à part les devices, tout est nouveau, et en QA ) comme je faisait un a deux backup par jour les services redémarrais donc , je n'ai pas eu de reboot. Dimanche matin, j'ai mis ma HC3 sur alimentation secouru, donc Arrêt propre et remise en service. Cette nuit à 5h00 j'ai un reboot : les graphes de CPU et RAM (dans domocharts sont normaux) et à cette heure la HC3 ne fait rien de particulier. Bon c'est à suivre, je sais que j ne suis pas le seul ... Par contre à 7heures (quand j'ai découvert que la la box avait rebooté ) je n'ai pas pu me connecter à la HC3 depuis Opéra/mac Os comme d'habitude) La HC3 était bien OK puisque accessible depuis macOS/Safari et Home Center, les applis externes qui lisent et écrivent dans la HC3 tournaient. J'ai vidé le cache de Opera, killé puis relancé Idem. J'ai essayé depuis macOS/Chrome impossible de se connecter non plus. Depuis macOS/Firefox c'est OK ??? J'ai rebooté mon Mac, idem. J'ai rebooté la HC3 Idem. Je me suis connecté sur la box avec un andoid par Opera et Chrome OK 10 à 15 minutes après tout est rentré dans l'ordre pour Mac/Opéra et Mac/Chrome Bizarre mais pas bien grave
-
Topic unique Caméras Réseau IP Hikvision
henri-allauch a répondu à un(e) sujet de Lazer dans Caméras
Une idée non mais cela m'est arrivé il y a quelques mois. Et cela a refonctionné quelques semaines après sans rien modifier Je n'ai rien trouvé pourtant mes mails ne partent plus par les serveur fibaro. La boîte mail en réception est sur Gmail. Le lecteur de mail est sur osx Catalina. J'ai soupsonné le couple osx mail et Gmail qui ne font pas toujours bon menage -
Conclusion: Donc le problème initial c'est bien l'utilisation de setInterval qui pouvait relancer une requête sans que la première ne soit terminée. Après remplacement par setTimeout c'est correct. Mais comme j'avais laissé mes traces, je me suis fait piéger par un last=lastResfresh qui est normal. ( j'ai ajouté dans la trace events et changes ) [24.04.2021] [15:14:55] [WARNING] [QA_CONTROLEVENEMENTS--SIMPLIFIE__342]: ATTENTION -> lastRefresh : 81040 states.last : 81040 -> {"status":"IDLE","last":81040,"date":"15:14 | 24.4.2021","timestamp":1619270095,"events":[],"changes":[]} Avec events [] et changes[] VIDES Fin ( Je l'espère ) Merci à vous deux
-
OK effectivement il faut que je regarde le contenu du premier et du 2eme un des deux devrait être sans événements alors ?? Et s'il y a les mêmes dans les 2 ignorer si last=lastResfresh pour ne pas traiter 2 fois
-
Et comme disait Robert Lamoureux, ....... et le canard était toujours vivant Après avoir modifié mon code avec les setTimeout hier, j'ai toujours (dans le QA complet ) à la sortie de la requête refreshStates, des states.last égales au last de la requête précédente Certes moins nombreuses, mais autour de 10 à 20 par heure pour des cycles à 1 secondes. J'ai fait plein d'essais avant de reposter ici / augmentation du cycle a 1,5 secondes diminution à 0,1 secondes, il y en a toujours. Ajout de timer pour le net.hppClient Idem Sur un essai en code réduit, il me semble que si je supprime le traitement checkEvents lancé si succes, je n'ai plus ce problème. Si je comprend bien dans GEA, sur succes la recherche des évenements est en partie réalisé dans le on succes, ce qui fait que la requête refreshStates suivante est lancée après ce traitement. Alors que dans mon cas sur succes j'appelle la fonction checkEvents qui a son tour va appeler event ... donc la requête refreshStates suivante est lancés en // de ces traitements. Le problème est peut être là ??? je vais continuer mais ??? Ma boucle actuelle et en piece jointe le Qa complet au cas ou quelqu'un a une idée function QuickApp:start() -- Initialisation local lastRefresh = 0 math.randomseed(os.time()) local urlTail = "&lang=en&rand="..math.random(2000,4000).."&logs=false" -- Boucle d'attente d'événements instantanés local function loop() local stat,res = self.http:request("http://127.0.0.1:11111/api/refreshStates?last=" .. lastRefresh ..urlTail, { success=function(res) local states = res.status == 200 and json.decode(res.data) if states then if states.last == lastRefresh then self:warning("<font color=red>", "ATTENTION -> lastRefresh : ", lastRefresh, "states.last : ", states.last ,"</font>") end --self:warning("<font color=green>", "OK -> lastRefresh : ", lastRefresh, "states.last : ", states.last ,"</font>") lastRefresh=states.last if states.events and #states.events>0 then checkEvents(states.events) end end setTimeout(loop, self.refreshInterval) end, error = function(res) self:error("Error : refreshStates : " .. res) setTimeout(loop, 2 * self.refreshInterval) end, }) end -- Lancement initial de la boucle loop() end QA Complet.lua
-
J'ai galéré pour le mettre en évidence car la mise en place de trace modifie les timing et l'erreur n'est plus visible. Je vais donc mettre en place la méthode avec setTimeout () ... à tête reposée. Pour l'histoire c'est à la migration de mon dernier device (une télécommande figaro) que j'ai ressenti les doubles évènements C'est le seul device ( dans mon cas) qui utile le CentralSceneEvent pour passer la Key et ses attributs. merci @jjacques68 @Lazer et @jang de vos conseils
-
@jjacques68 il n'y a pas de setTimeout, c'est le setinterval qui doit lancer la boucle chaque seconde et il le fait. Mais comme toi je pense à un desynchro J'ai regardé dans GEA la méthode de @Lazer et j'ai fait un mini QA ( donc là il y a setTimeout ) Et .... je n'ai pas le problème, avec ou sans warning de trace J'aimerai avant de modifier définitivement ma boucle initiale qui malgré tout fonctionne ""Presque bien " ton avis et celui de @lazer s'il a une minute .. ou 2 function QuickApp:onInit() __TAG = "TEST-STYLE GEA" .. plugin.mainDeviceId self:trace("") self:trace("QuickApp TEST-STYLE GEA - Initialization") self:trace("") self.refreshInterval = 1000 -- durée en millisecondes self.http = net.HTTPClient() self:start() end function QuickApp:start() -- Initialisation local lastRefresh = 0 -- Boucle d'attente d'événements instantanés local function loop() local stat,res = self.http:request("http://127.0.0.1:11111/api/refreshStates?last=" .. lastRefresh, { success = function(res) local states = json.decode(res.data) if type(states) == "table" then if states.last == lastRefresh then self:warning("<font color=red>", "ATTENTION -> lastRefresh : ", lastRefresh, "states.last : ", states.last ,"</font>") end --self:warning("<font color=green>", "OK -> lastRefresh : ", lastRefresh, "states.last : ", states.last ,"</font>") lastRefresh = states.last or 0 self:traitement(lastRefresh) end setTimeout(loop, self.refreshInterval) end, error = function(res) self:error("Error : refreshStates : " .. res) setTimeout(loop, 2 * self.refreshInterval) end, }) end self:warning("ICI Start Loop") loop() end function QuickApp:traitement(last) self:warning("<font color=yellow>" , "traitement(last) :", last, "</font>") end Style GEA.lua
-
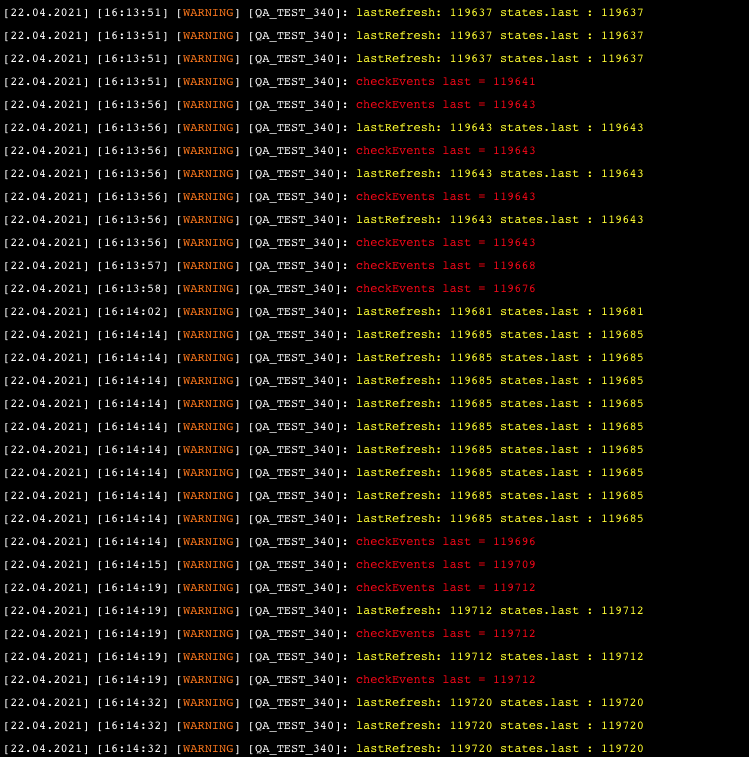
Thank's but it's the same PB for example 119643 is processed more than once
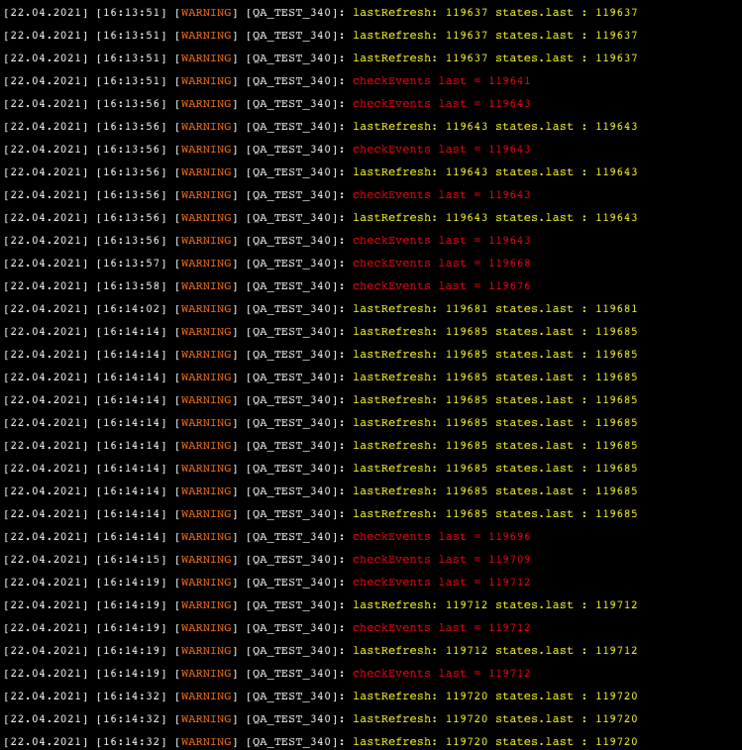
-
J'ai de temps en temps des actions doublées dans le traitement du refreshStates ( méthode issue des exemple ci -dessus et du forum officiel ) Je ne comprend pas pourquoi, j'ai donc simplifié le Qa sans traiter les évenements, il s'avère que je traite plusieurs fois la même sortie de la requête HTTP refreshStates ( le meme lastRefresh ) local function pollRefresh() --self:warning("<font color=green>", "Request with lastRefresh: ", lastRefresh ,"</font>") --*****Si on ajoute ce warning tout va bien***** local stat,res = self.http:request("http://127.0.0.1:11111/api/refreshStates?last=" .. lastRefresh, { success = function(res) local states = json.decode(res.data) if states then if lastRefresh == states.last then self:warning("<font color=yellow>", "lastRefresh: ", lastRefresh , " states.last : ", states.last ,"</font>") end lastRefresh=states.last if states.events and #states.events > 0 then checkEvents(states.last) end -- Henri last pour debug only) end end, error = function(res) self:error("Error : refreshStates : " .. res) end, }) end --pollRefresh Dans l'exemple et le QA joint, si je valide le warning ( ligne 26 ) avant la req Http, tout va bien : on voit en vert les req avec le lastrefresh qui évolue , et s'il y a lieu on part dans le checkevent() Si j'enlève ce warning on voit en jaune je résultat du warning (ligne 32 ) le state.last issu de la req est = à l'ancien et on part dans checkevent() donc plusieurs fois avec les mêmes évenements. Si je passe l'interval à 2 secondes je diminue ou supprime ce problème ( coome en ajoutant le warning avant la req ) Il y a un pb de timing que je ne maitrise pas. Cela explique peut être mon post un peu plus haut qui signalait un plantage acev un polling à 0 j'ai besoin d'un expert ... QA refreshStates.lua

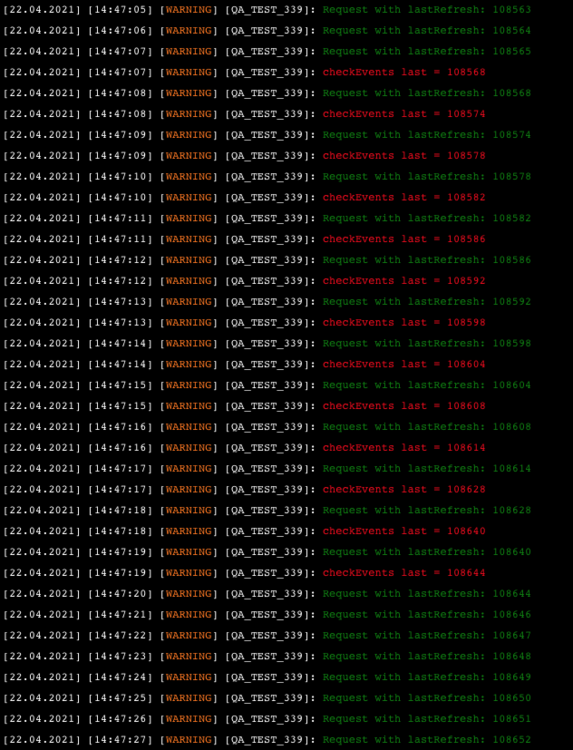
-
Nouvelle application mobile pour smartphone Fibaro Home Center / Yubii Home Center
henri-allauch a répondu à un(e) sujet de fredokl dans Applications Smartphones et Tablettes
J'ai bien un retour du qa sur ios et android J'ai déjà eu l absence de retour même avec la version précédente c'est bizare -
Nouvelle application mobile pour smartphone Fibaro Home Center / Yubii Home Center
henri-allauch a répondu à un(e) sujet de fredokl dans Applications Smartphones et Tablettes
Pour moi les QA c'est un peu long mais ils remontent bien -
topic unique Fibaro Keyfob FGKF-601 - Télécommande porte-clés Z-Wave+
henri-allauch a répondu à un(e) sujet de d@m!Ch94 dans Modules Fibaro
Message erroné et supprimé Désolé -
topic unique Fibaro FGR-223 - Roller Shutter 3 - Micromodule pour volet roulant Z-Wave+
henri-allauch a répondu à un(e) sujet de Lazer dans Modules Fibaro
J'ai deux stores bannes. Maintenant Sur HC3 L'un est piloté par des boutons poussoirs et par un FGR-222. La calibration s'est bien passée ( en partant du store déployé : enroulement, déroulement, enroulement ) Le câblage est conforme aux documents, les poussoirs actionnent correctement le bon sens du moteur, Les commande depuis la HC3 sont aussi dans le bon sens de montée et descente La commande depuis l'application HomeCenter Android ou IOS fonctionne Tout est parfait sauf q'un store banne c'est l'inverse d'un store : quand on dit que le store est ouvert a 100% c'est qu'il est enroulé, dans le cas s'un store banne il est enroulé aussi mais ouvert a 100% c'est une désignation fausse. Donc dans les commandes, dans un QA il faut dire : fibaro:call(ID, "open") pour fermer le store banne ( l'enrouler ) et fibaro:call(ID, "close ") pour le dérouler le store banne et boire le pastis à l'ombre Bon je n'ai pas trouvé de solution pour modifier la désignation des labels. J'ai mis mes propres icônes pour avoir une représentation correcte. Le second est piloté idem avec un autre jeux de poussoirs et un FGR-223 on est dans le même scénario que la description ci-dessus sauf pour l'application HomeCenter Android ou IOS . J'ai sur l'écran v ^ ||| ( comme pour le FGR-222 ) mais si on appui sur v pour descendre les store banne le carré qui doit remplacer le v pour pouvoir arrêter le mouvement ne s'affiche que furtivement. Donc on ne peut pas arrêter. Sur le FGR-222 c'est OK Vous avez le même comportement aussi ou il y a un paramètre incorrect !!